Probabilities - Concept & Theory#
FIZ371 - Scientific & Technical Calculations | 03/03/2021
Emre S. Tasci emre.tasci@hacettepe.edu.tr
import numpy as np
Note
The text for this lecture note is a summarized version of the 2nd chapter of David MacKay’s wonderful book “Information Theory, Pattern Recognition and Neural Networks” (which also happens to be our main source book).
Basic Distributions, Entropy and Probabilities#
Ensembles#
An ensemble \(X\) is a triple system: \(\left(x,A_x,P_x\right)\) where:
\(x\): is our random variable,
\(A_x\): is the possible value set,
\(P_x\): is the probabilities set
Example: Frequency of letters of the alphabet.
Sub-ensemble probabilities#
If \(T\) is a sub-ensemble of \(A_x\), then:
(The probabilities are added)
Joint Ensemble#
\(P(x,y)\): The joint probability of \(x\) and \(y\)
(Notation: \(x,y\leftrightarrow xy\))

Fig. 1 The probability distribution over the 27×27 possible bigrams xy in an English language document, The Frequently Asked Questions Manual for Linux. (Fig. 2.2 in MacKay)#
Marginal Probability#
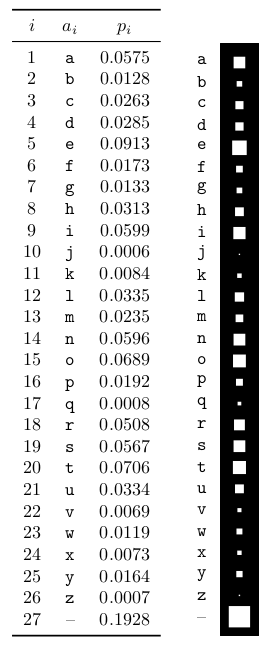
Fig. 2 Probability distribution over the 27 outcomes for a randomly selected letter in an English language document (estimated from The Frequently Asked Questions Manual for Linux ). The picture shows the probabilities by the areas of white squares. (Fig. 2.1 in MacKay)#
Conditional Probability#
“Given that \(y=b_j\), what is the probability that \(x=a_i\)?”
Example: Letters in alphabet in a bigram (a word with two letters) \(xy\)
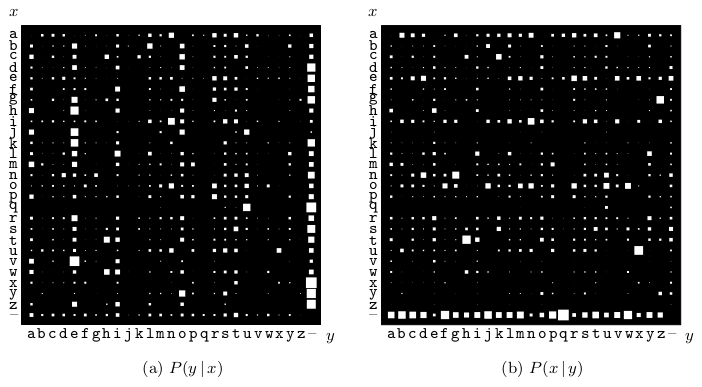
Fig. 3 Conditional probability distributions. (a) P (y | x): Each row shows the conditional distribution of the second letter, y, given the first letter, x, in a bigram xy. (b) P (x | y): Each column shows the conditional distribution of the first letter, x, given the second letter, y. (Fig. 2.3 in MacKay)#
Multiplication Rule#
Here, \(H\) symbolizes the “universe”, i.e., given everything else as it is.
Summation rule#
Independency#
For \(X\) and \(Y\) to be considered independent of each other, they should satisfy:
Example#
Jo takes a medical exam.
Variables are:
a: Jo’s health:
a = 0: Jo is healthy
a = 1: Jo is sick
b: Test result:
b = 0: Test result is negative
b = 1: Test result is positive
Data:
Test is 95% reliable
The probability that somebody at Jo’s age, status and background to be sick is 1%
Jo takes the test and the result turns out to be positive (indicating that Jo is sick). What is the probability that Jo is indeed sick?
Conditional
Marginal
Now that we have all the probabilities we need, we can move on to the calculation:
Hence, there is a 16% probability that Jo is indeed sick.
(0.95*0.01) / (0.95*0.01 + 0.05*0.99)
Information Content#
Suppose that we want to use a coding similar to that of the Morse Coding.

Should we assign a single dot to “e” or “j”?
We must assign the shortest symbols (like “.” or “-”) to the most frequently used letters and long symbols (like “…” or “.-.” to the infrequently used letters to reduce the transmission time. This is reflected and calculated by the information content \(h(x)\):
which is measured in units of bits.
Entropy#
Entropy, \(S\), in this context, is defined as the average information content:
\(\rightarrow\,S(x)\ge 0\) (only equal to 0 when \(p_i = 1\))
\(\rightarrow\) entropy is maximum when \(p\) is uniform (equal probabilities)
Expected (Average) Value#
\(\{x\} = \{1,3,3,5,7,7,7,8,9,9\}\)
\(<x> = \frac{1+3+3+5+7+7+7+8+9+9}{10}=5.9\) (“Conventional” method)
x = [1,3,3,5,7,7,7,8,9,9]
p = [0,0,0,0,0,0,0,0,0,0]
size = len(x)
for i in range(1,10):
p[i] = x.count(i) / size
p
x_avg = 0
for i in range(1,10):
x_avg += i * p[i]
print(x_avg)
Variance \((\sigma^2)\)#
var = 0
for i in range(1,10):
var += i**2 * p[i]
var -= x_avg**2
print(var)
Standard Deviation \((\sigma)\)#
x2_avg = 0
for i in range(1,10):
x2_avg += i**2 * p[i]
print(x2_avg)
(x2_avg - x_avg**2)**0.5
var**0.5